


Shawn Meyers (@1dizzygoose), Principal Architect
Recently during a discussion on patching of Availability Groups (AG), the topic of snapshots for virtual machines came up. If I have an AG running in a virtual environment, can I do a snapshot and revert the snapshot without breaking the AG? Well we talked through it and figured it would probably break the AG. So, I decided to do some testing and find out for sure, hence this blog post. Should I give you the answer now, or should I make you read the whole blog post while showing the steps taken to verify the answer? Being the nice guy that I am, I’ll give you the answer. Which is that with virtual snapshots, you can revert a SQL Server to a previous state and the AG will automatically recover, until you take a log backup. Meaning as long as the log hasn’t been cleared, you can roll back. Make sure you stop your log backups during patching if you are taking snapshots. I will cover the proper way to patch an AG in a blog post in the near future.
So why would you want to take a snapshot of a VM prior to patching? You have an AG, so you can run on the other node. But what happens if the patch causes issues or hangs? Having a simple way to roll back to a previous state is crucial. While I have rarely seen OS corruption, it does occur and usually as part of a patch. Therefore, having a snapshot is an easy way to roll back and recover – instead of spending hours trying to figure out how to fix it, or reinstalling the OS, or deploying a new VM. All of which will cause the AG to break as well, so even if the snapshot breaks the AG, I would still want to do it. Thankfully, the AG does not break it and things work just fine.
Lab Setup
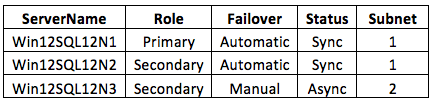
I have a three node AG in my lab. One primary and two secondary nodes, which span two subnets, so I can test multi-datacenter designs.
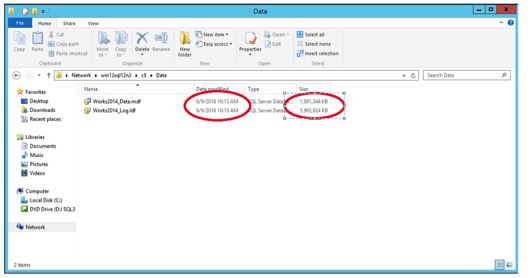
I have four databases in the AG, but I am only going to play with the Adventure Works 2014 database. Everything was green when I started my testing and the file sizes were small, 210 MB. I took the snapshot of the second node in the AG. The graphic below shows file sizes and time stamps as they are easier to verify than database properties.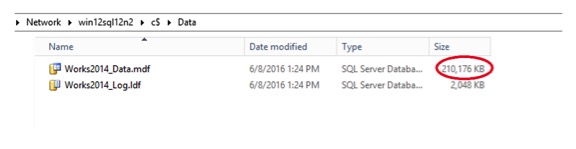
I ran a script from Jonathan Kehayias in order to make the Adventure Works database grow (you can find the specific script here). I put a decent amount of data change into this test to ensure it can handle any size change.
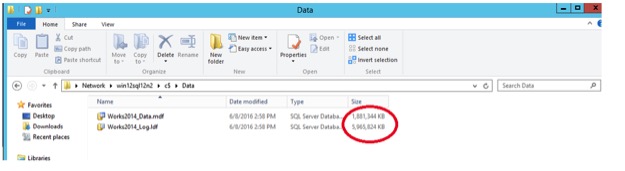
Notice how the files grow. After about an hour, and the .mdf is now 1.8GB. Next, revert the snapshot. The files dates changed back, and the log file started to show changes before I could get a screen shot. MDF is back to 210 MB.
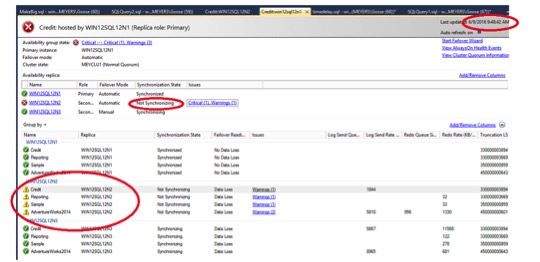
In the AG dashboard, we see errors. The state is listed as not synchronizing, there are alarms, and the dashboard shows data loss. This is right after the snapshot revert occurred.
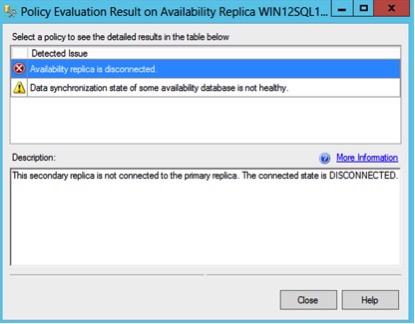
If I look at the policy warning, it shows the node is disconnected. This is because the node disconnected when I reverted the snapshot back.
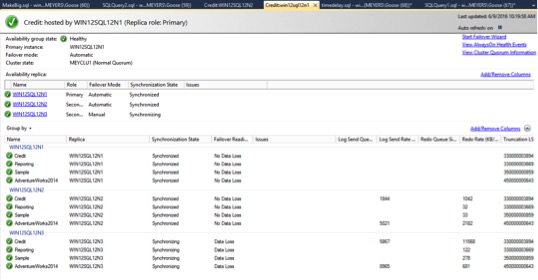
Give the AG some time to figure out what just happened. It was talking just fine, and then all of a sudden one secondary says it has old data. After about five minutes, it shows it is synchronizing. The AG queried the secondary to find last the log record it has received, found it still has the record in the current log, and started to send the transactions from that point forward. Granted it will take a while, as there was over a gigabyte of data changed and it is running on a spinning disk on my laptop. The other databases in the AG reported as synchronized almost instantly.
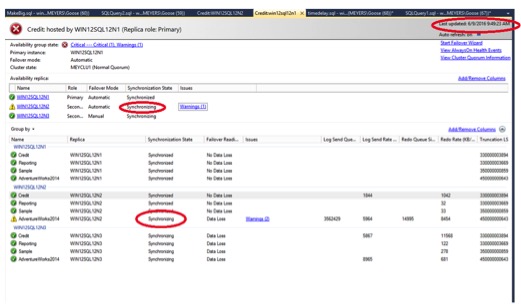
About 30 minutes later, the AG has finally caught up, and the status shows as Synchronized. The warning below is a policy I have setup to demonstrate that the RTO is greater than one minute. The whole log has been sent to the secondary, but the redo log has not yet been applied at the secondary. If a failover occurred at this point, there would be no data loss, but the redo log would need to finish applying prior to accepting new connections.
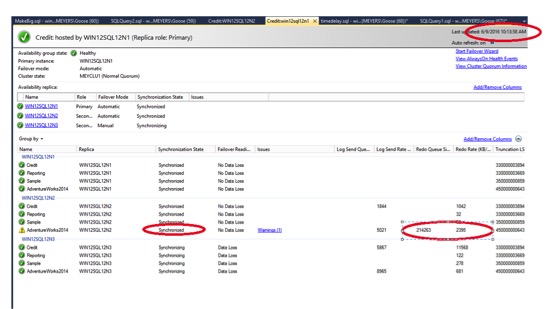
The AG is now all caught up, and the redo log is clear. Snapshots can be used when patching AGs and you can revert the snapshot with no issues, as long as you haven’t taken a log backup. Keep in mind, that in most cases, your revert would not have over a GB of data changes, it would be on much faster hardware, and your recovery would be much quicker.
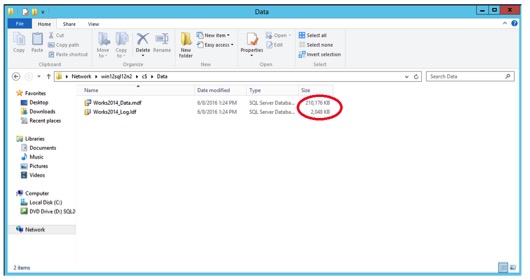
Database file sizes have returned to the same size they were before the revert snapshot.
So, what could break when rolling back a snapshot on an AG? My assumption is that backups are being taken and the log reuse status is clear.
We have taken a log backup. Next let’s look at the log reuse wait:
select name, log_reuse_wait_desc from sys.databases where database_id = 13
The log reuse wait shows NOTHING for all databases.
Next we revert the snapshot again. Notice how the data stamps went back to the start and the MDF is back to 210 MB.
We see the same errors in the AG dashboard.
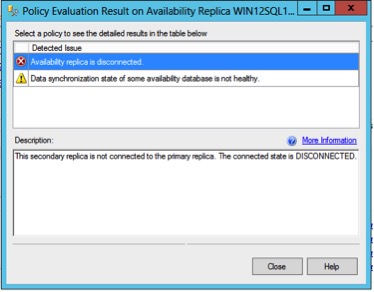
So we wait for a while for the AG to figure out what is going on, but we see no change. It is not starting back up. Looking at the AG databases, we see the pause sign on the Adventure Works 2014 database.
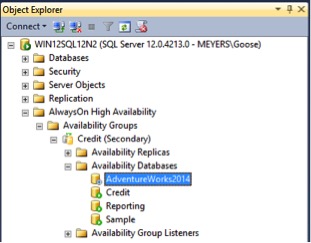
We right click on Resume Data Movement, but will it work?
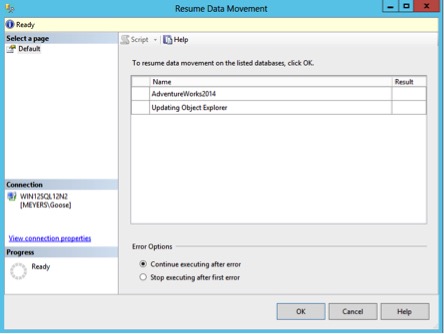
We don’t see any errors, but it also hasn’t fixed the issue. Time to go read the logs.
Date 6/9/2016 10:32:54 AM
Log SQL Server (Current – 5/23/2016 12:37:00 PM)
Source spid50s
Message
The remote copy of database “AdventureWorks2014” has not been rolled forward to a point in time that is encompassed in the local copy of the database log.
The log is telling us that the database on the secondary is not encompassed by the log. So doing a log backup will break the ability to roll back from a snapshot.
As a resolution, we take the log backup and apply it to the secondary with NO RECOVERY and resume, the AG will then recover.
In this article, I discussed how to take a snapshot and revert that snapshot without breaking the AG. In my next blog, I will cover the proper way to patch an AG.


