



Dave Welch (@OraVBCA), CTO and Chief Evangelist
The most impressive session I have taken in from the last two VMworlds was 2011 US session BCO2874 “vSphere High Availability 5.0 and SMP Fault Tolerance – Technical Overview and Roadmap”. This session was reprised at VMworld 2012 as session INF-BCO2655 “VMware vSphere Fault Tolerance for Multiprocessor Virtual Machines—Technical Preview and Best Practices”. Don’t miss these sessions’ live demo of a 4 vCPU workload failover.
I’ve been watching Fault Tolerance (FT) eagerly since Mendel Rosenblum did a live demo of FT alpha code at VMworld 2007. Alas, FT’s 2009 GA release has been little more than bait for future capability to House of Brick customers as none of those customers’ Tier-1 workloads fit inside FT’s current single vCPU limit.
I wonder if VMware’s executive leadership has any idea what it is sitting on with SMP Fault Tolerance (SMP FT). I’m wondering if SMP FT could turn out to be the most disruptive technology anyone has seen in years. SMP FT certainly threatens a massive disruption to the clustered relational database market. I make that prediction due to two key SMP FT features that Oracle RAC can’t touch: approximately single-second failover, and no client disconnect.
The VMworld 2012 US session included engineering’s confession that the alpha code still has very substantial performance latency (they use the word “overhead”, which I am replacing with “latency” for clarity). I got the impression that they’re quite worried about the latency, and wondered if they even considered their current performance numbers fatal to a GA release. Here’s a screen shot of their latency numbers (at video minute 35):
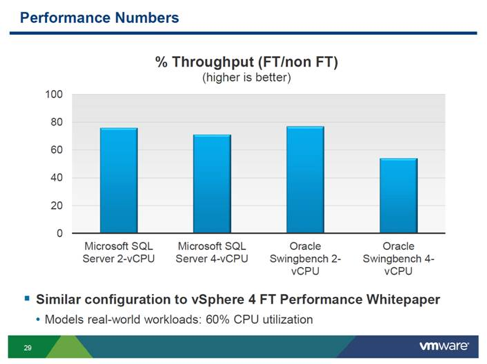
The presenters then refer participants to the vSphere 4 FT Performance Whitepaper (“Section 3. Fault Tolerance Performance” beginning on p. 7) for further elaboration on their performance measurement methodology.
I’m betting there are plenty of extremely HA SLA-sensitive workload owners that will be more than happy to tolerate that much latency. For example, look no further than the stock exchanges where extremely distributed transactions must commit all transaction phases within a few seconds to avoid substantial revenue loss let alone regulatory penalties.
A corollary to Moore’s law is Intel executive David House’s prediction that chip performance would double every 18 months. I’ve read clarifications by other parties arguing that chip performance actually doubles every 20 to 24 months. Fine. Let’s call it 24 months. In his 2006 blog post, John Sloan extends that math to a 30-fold performance improvement each decade. (Related to that, my non-scientific mental survey tells me that less than 10% of House of Brick’s performance diagnostic engagements find CPU-constrained workloads.) In light of the fact that we are swimming in a world of CPU performance and it just keeps getting better, how obsessed do I imagine I’d be with SMP FT’s latency if I were the CTO of NYSE or NASDAQ? Not very. I could stand up my SMP FT-protected workload in a hardware refresh and still run circles around any x86 chip vendor’s offering of just two hardware depreciation lifecycles ago.
Accordingly, I suggest the SMP FT product and engineering teams gate the product’s dot-zero release based on code stability only. Subsequent to that, I suggest the engineering/product teams prioritize their engineering efforts as follows:
- Stability
- vCPU horizontal scalability
- Latency (and a distant third at that)
During the 2012 VMworld SMP FT session Q&A, Jim Chow answered a question by saying that SMP FT engineers were still considering the subject of the question in their architectural discussions. That answer gave me the impression that SMP FT’s GA release was probably at least a year away at that time. Despite the wait, I believe enterprises would do well to evaluate SMP FT’s business continuity promise now and get project planning underway accordingly.


