



In this post, we will discuss integrating data that is housed in AWS S3 with SQL Server RDS. One of the advantages of running a database in RDS is that you are not responsible for the Operating System – or the underlying hardware. However, in the event you are tasked with uploading data from an external data source to RDS–this can be a problem as RDS does not allow access to local storage. AWS has recently allowed the integration of RDS with S3 by creating a local drive D:\S3 which is accessible from RDS. Recently I was working with a client that needed to create an ETL process to import a large number of CSV files into a table residing in SQL RDS. It was a very interesting project and in the spirit of sharing, hopefully this blog will help someone else who is tasked with importing / exporting data to or from S3.
Requirements for SQL Server RDS S3 Integration
In order to import files from S3 to RDS you will need to have the correct policies and permissions in place. The pre-requisites are:
- IAM Policy and Role created
- IAM Role added to the SQL RDS Instance
The first requirement for connecting RDS with S3 is to have a policy that can access the S3 Bucket. For this example, we will be creating a policy called s3rds_pol. The policy should have the following permissions set for the S3 service:
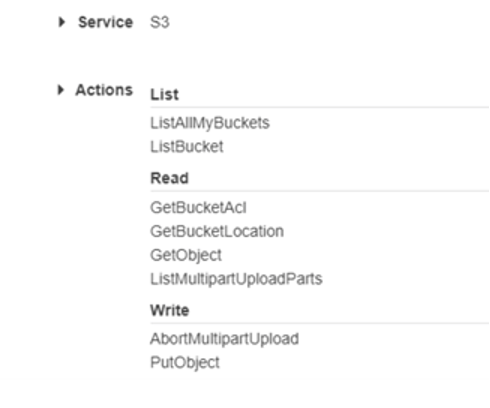
After the policy has the appropriate permissions, we need to assign the policy to a resource. The resource can be a specific bucket or object within a bucket, or it can be applied to all resources. As a best practice you should not grant all resources.

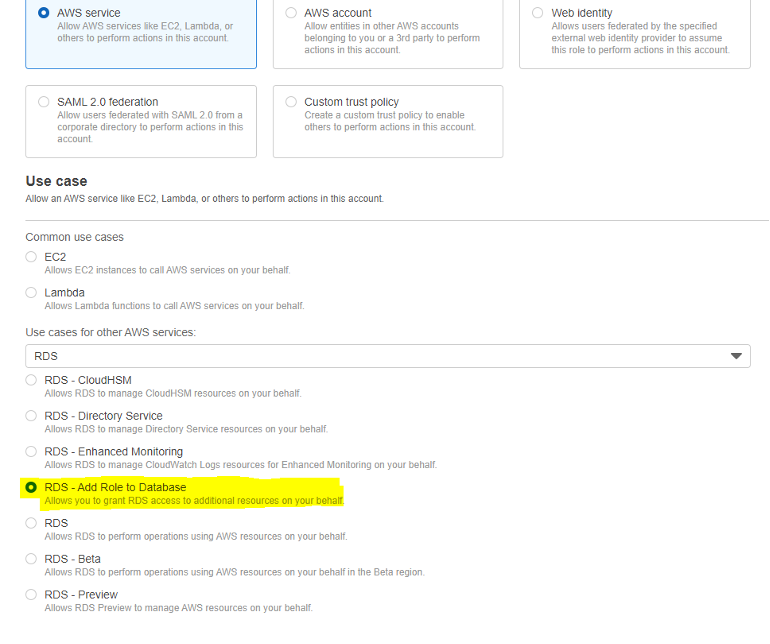
Now that the policy has been created and applied to a specific bucket – we need to assign the policy to an IAM role. We will be creating a new IAM ROLE and selecting the RDS – Add Role to Database as the “Use case” in the AWS console – as pictured below.
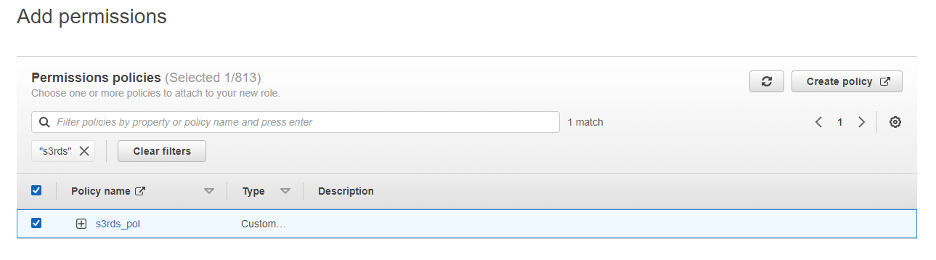
Next we will need to attach the Permission Policy we created, which we called s3rds_pol.
Now that we have the appropriate IAM Role and Policies created we need to add this role to the RDS instance. This can be done be selecting the Connectivity and Security tab from the RDS instance. In this tab you will need to select the role and the S3_Integrations feature from the drop down boxes.

Once the changes are confirmed and have taken effect the status will change to ACTIVE and you can begin downloading files from S3 to RDS.
Downloading Files from Amazon S3 to SQL Server RDS
SQL RDS will have several Amazon supplied stored procedures located in the MSDB database. These stored procedures are intended to be called when downloading files from S3 or when reading or deleting files from the D:\S3 directory within RDS.
As an example, to download a file from S3 to RDS you can issue the following command:
exec msdb.dbo.rds_download_from_s3
@s3_arn_of_file=’arn:aws:s3:::<bucket_name>/<file_name>’,
@rds_file_path=’D:\S3\<custom_folder_name>\<file_name>’,
@overwrite_file=1;
The first parameter @s3_arn_of_file is the ARN of the file you would like to download.
The second parameter @rds_file_path is the location where you would like the file to be downloaded in the D:\S3 directory
The third parameter @overwrite_file is a flag 1 to overwrite 0 to not overwrite the existing file if it exists in the current download location.
Monitoring Download Tasks with rds_fn_task_status
Once you have executed the command you can see the task_id (which we will need later on) as well as the status of the current command by running:
SELECT * FROM msdb.dbo.rds_fn_task_status(NULL,0);
The rds_fn_task_status function will show you the task_id, along with the current of all commands.
When the download task is complete you should see something like the following results:

After the file(s) have been downloaded to D:\S3 you can execute a rds_gather_file_details adding the task_id obtained from the previous step to list the files we currently have available to the RDS for the supplied task_ID.
This function will add another command to the queue similar to the download procedure call. After the rds_gather_file_details command is finished – you can query the results by running
SELECT * FROM msdb.dbo.rds_fn_list_file_details(TASK ID);
After you have downloaded and processed the files in RDS – you will need to delete the files from the RDS (D:\S3 This can be completed by running the following command
Deleting Files from RDS After Processing
exec msdb.dbo.rds_delete_from_filesystem
@rds_file_path=''D:\S3\'+@filenames+'''
The rds_delete_from_filesystem procedure has only one parameter, @rds_file_path, which should contain the path and file name of the file you are trying to delete. Keep in mind that deleting the file from RDS will have no impact on the file located in the S3 bucket.
Limitations of Amazon RDS and S3 Integration
Users planning on making extensive use of this feature should be aware of a few limitations:
- The RDS and S3 bucket must be in the same region, currently AWS does not support cross region integration.
- Each file you are attempting to download will require a separate execution of the rds_download_from_s3 procedure. Currently AWS does not support passing wildcards or multiple file names.
- The max file size you can download is 50 GB.
- The D:\S3 contents are local to the RDS and will not failover if you have a multimode instance.
- You cannot exceed 100 files in the D:\S3 directory.
- Commands will be processed one at a time, there is currently no option to run multiple commands in parallel.
- Only the following file formats are supported .bcp, .csv, .dat, .xml, .txt, .tbl, .fmt, .info, and .lst.
Working in AWS RDS is always a fun challenge because there are so many traditional tasks such as ingesting files, which we need to handle using different methods and technologies than we might be familiar with doing similar tasks in an on-premises environment.
Expert Help with SQL Server RDS S3 Integration
If you are running into similar challenges and need expert help, please feel free to reach out to House of Brick as we are always happy to discuss. Also please be on the lookout for the next article in which we will go over how to automate this process by calling the download and delete procedures dynamically.



