Overview
With all of the database platforms and cloud service providers available, it is becoming more likely that companies will have databases running on multiple engines. We at House of Brick were recently tasked with an interesting project from one of our customers where they had an on-premises SQL Server instance, and an Aurora PostgreSQL RDS instance running in AWS: the customer wanted to have the ability to write queries to join tables from both databases.
To allow this, we had to edit the AWS security groups and create a linked server on the SQL Server instance to the Aurora instance. This blog will not go into details on how we set up the infrastructure to allow us to connect from an on-premises SQL instance to an Aurora PostgreSQL RDS; this blog will focus on the potential pitfalls that you may encounter when trying to execute queries using a linked server connection. We will look at the issues and discuss why they are happening and how you can avoid them so that your workload will run more efficiently.
Current Configuration
We will be using a table named Customer in both databases (SQL, Aurora PostgreSQL). The Customer table will have the following schema and sample records:
- CustomerID is the Primary Key and Clustered Index
- The table contains two Non-Clustered Indexes, and they are on the LastName and Email fields
- Both tables contain 100,000 rows
| CustomerID | FirstName | LastName | Phone | Street | City | State | |
|---|---|---|---|---|---|---|---|
|
ACME |
Tom |
Jerry |
123-123-1234 |
Tjerry@aol.com |
12 Abc Ave |
NY |
NY |
|
Zappy |
Mike |
Western |
234-234-2345 |
Jjones@ms.com |
132 Abc Lane |
NY |
NY |
SQL Query
We will begin our example with a query executed against our SQL Server instance. The query we will be using is:
Select LastName
From dbo.Customer
Where LastName = ‘Jerry’
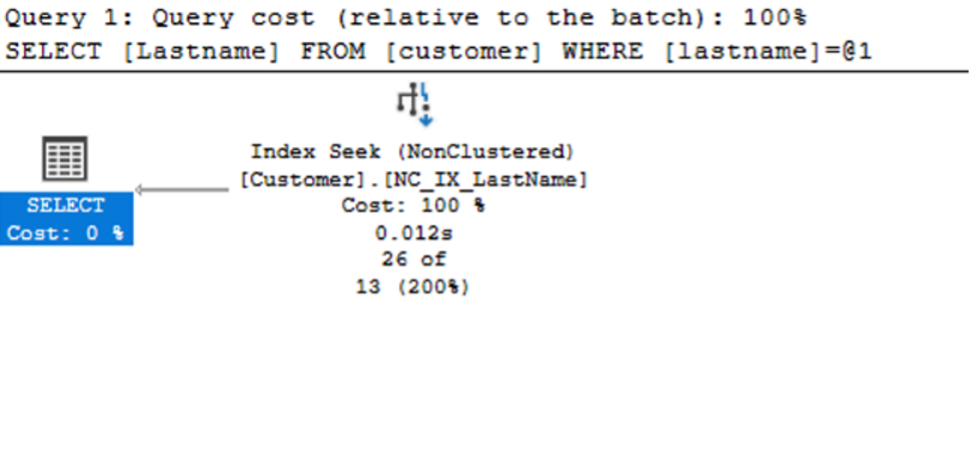
When we execute the above code on our SQL Server instance, we see that SQL Server performs an Index Seek on the NCI_IX_LastName index, returning the results in 43ms. Below is the execution plan.
Aurora PostgreSQL
Now we will run the above query on an Aurora Postgres database with the same schema and indexes as we had on the Customer table in our SQL Server instance. We can see the plan was the same as we saw with the SQL Server instance. This query was completed in 64ms. This is what would expect to see; the index was used on both instances.

Linked Server
We have confirmed that when running these queries locally on either the Aurora PostgreSQL or SQL Server databases we are getting the expected results. Now, we will try to execute this query on Aurora PostgreSQL, but this time coming from our SQL Server – using a linked server named aurora. The new code is as follows:
Select lastname
from [aurora].xdbamaint.public.customer
where lastname = ‘Jerry’
We have seen this query take less than 70ms when run on each host locally, but when running via a linked server from SQL Server to Aurora PostgreSQL the query takes over 5 seconds to return results.
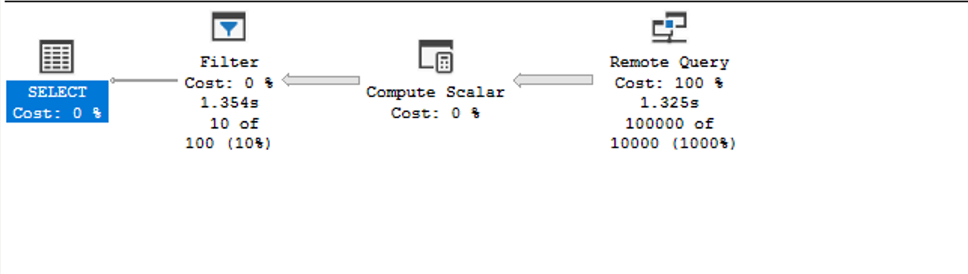
This is the execution plan – which unfortunately isn’t much help – because almost all of the cost is listed as remote query cost.
Issue
The reason this query took almost 10 times longer to complete compared to when run locally is because the filtering is not being handled on the Aurora PostgreSQL side; instead, the entire customer table is returned to the SQL Server side and then the “where” clause is applied and the data is finally returned. This is why we see the extra “filter” operation in the above execution plan.
Work Arounds
There are two ways to avoid this type of behavior when it comes to running queries via linked server from SQL Server to Aurora PostgreSQL. The first option is to create a view on the Aurora PostgreSQL instance. This view will force Aurora PostgreSQL to filter out any data not needed to satisfy the requested query. The full execution will now be completed on the Aurora PostgreSQL instance.
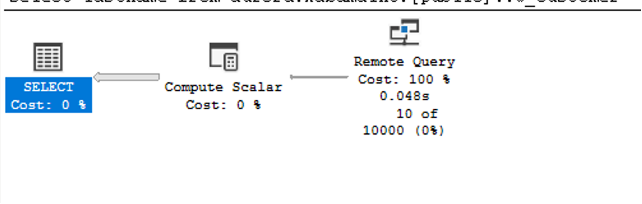
By executing this query calling a view on the Aurora PostgreSQL instance, we can see there is no longer the filter operation in the execution plan and the query took 72ms, which is much closer to the execution times we were seeing when running locally.
The second method for forcing the execution on the Aurora PostgreSQL instance is to use OpenQuery. When executing code via OpenQuery all of the filtering and calculations will be handled on the Aurora PostgreSQL instance, similar to if you were to run locally or use a view as outlined above.
OpenQuery has multiple advantages over using views, mainly not having to create a view for every query you will be executing. Another advantage is you can use Aurora PostgreSQL SQL formatted queries as seen with the “limit 1” being added to the new code below.
SELECT * FROM OPENQUERY (aurora, 'Select lastname
from xdbamaint.public."Customer"
where lastname = ''Saint''
limit 1')
The new execution plan generated using OpenQuery is shown below. This query took 68ms – right on par with what we were expecting to see.

Closing
This blog has shown some of the potential performance issues that are commonly seen when executing linked server queries between SQL Server and Aurora PostgreSQL. We also discussed why these issues are happening and how to avoid them, and we provided two viable options. Creating the views on the source server is beneficial for repeatable queries, whereas OpenQuery is best suited for ad-hoc queries.
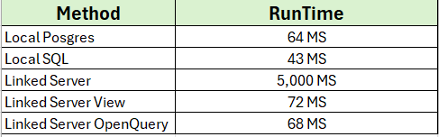
But, as we have seen in the above examples, both methods will improve performance when executing queries via a linked server from a SQL Server instance to an Aurora PostgreSQL database (or a native PostgreSQL database (RDS or EC2)). Below is a summary of the execution times for each method used to execute the queries.