




Dave Welch (@OraVBCA), Chief Evangelist
Part II: Four Operational Best Practices
In this post, we discuss four RAC operational best practices for shops that have either strategically selected RAC or have been compelled to adopt it.
RAC operational best practices include:
- Understand RAC-literate coding and data administration
- Operationally test the RAC stack
- Layer RAC on vSphere
- The RAC break/fix lab
This post follows the Oracle RAC Dilemma: Part I blog, where we presented four criteria for implementing or maintaining RAC. In that post, we listed ways that single instance Oracle Database on vSphere is not RAC.
Understand RAC-Literate Coding and Data Administration
While some workloads require certain advanced high availability features that RAC offers, for a scalable workload on a taller symmetric multiprocessing (or SMP) node, the ability to scale adequately in RAC cannot be assumed. Furthermore, some workloads are not even compatible with RAC. The rules for proper RAC schema design and software development are much more rigid than those for single-instance workloads.
House of Brick has a clinic dedicated to RAC-literate coding and schema design, as designing, developing, and proofing for RAC can be arduous. The key to RAC scalability is to keep the high-speed dedicated network link, or interconnect, between the RAC nodes “quiet”. Two RAC nodes may both want to update the same data block at very nearly the same point in time. In that case, RAC maintains performance efficiency by moving the block directly between the instances’ caches. If transactions could be assigned to special purpose nodes, in such a way that inter-node block movement is eliminated, it would result in a completely “quiet” interconnect. A completely quiet interconnect translates to 100 percent scalability per node added to the RAC cluster, which is why pure read-only decision support applications can experience straight-line scalability on RAC, even with dozens of nodes.
It can be expensive and labor-intensive to configure dedicated native hardware RAC stacks throughout the release lifecycle. For this reason, it is unfortunately not uncommon for code targeted for RAC to encounter RAC for the first time in the last system stack before production.
Operationally Test the RAC Stack
A busy interconnect, on the other hand, can translate to per RAC node scalability that is significantly less than 100 percent. Such applications can be labeled “RAC hostile”. Detecting such RAC-challenged workloads demands that single instance workloads be operationally tested under RAC, which can be a significant additional burden to the product lifecycle that is largely moot with single-instance workloads.
In addition, some application code restricts execution to a single, hard-coded node name, rendering the module “RAC impossible.” Examples of such code are the Oracle-supplied packages DBMS_PIPE, DBMS_ALERT, and DBMS_SIGNAL.
If you take your chances and throw RAC-agnostic workloads to RAC, you’ll be okay in about 85% of cases in our observation. For the other 15%, you’ll be looking at opening up the project plan and taking the stack back to an earlier phase of the design/development lifecycle for necessary adjustments. That’s not only expensive, but may involve difficult interactions to notify business units and clients that there will be a substantial code GA delivery delay, as well as cascading delays into other projects.
Application teams may be compelled by one or more of the RAC value-added features mentioned in Part I of this series. On the other hand, the capabilities may be assessed to be primarily corner cases. As such, they may not merit the expense, project planning impact, or risks involved with RAC.
Layer RAC on vSphere
If your organization has sufficient business and technical justification to adopt (or keep) RAC, consider layering RAC on vSphere. Ultimately, RAC concerns IP, ports, and voting disk I/O. Therefore, the underlying vSphere infrastructure is invisible to the RAC stack. vSphere enables RAC deployment beginning with the first developer’s stack, efficiently, inexpensively, and without hardware dependencies. As such, vSphere significantly augments RAC’s functionality without the forced introduction of disadvantages.
As shared during the 2014 VMworld Oracle Customer Experience panel, three out of four of the panelists ran RAC. All of them raved about their RAC on VMware experience. All four panelists happened to be House of Brick clients. It also shouldn’t be a surprise that this session’s content is still relevant today.
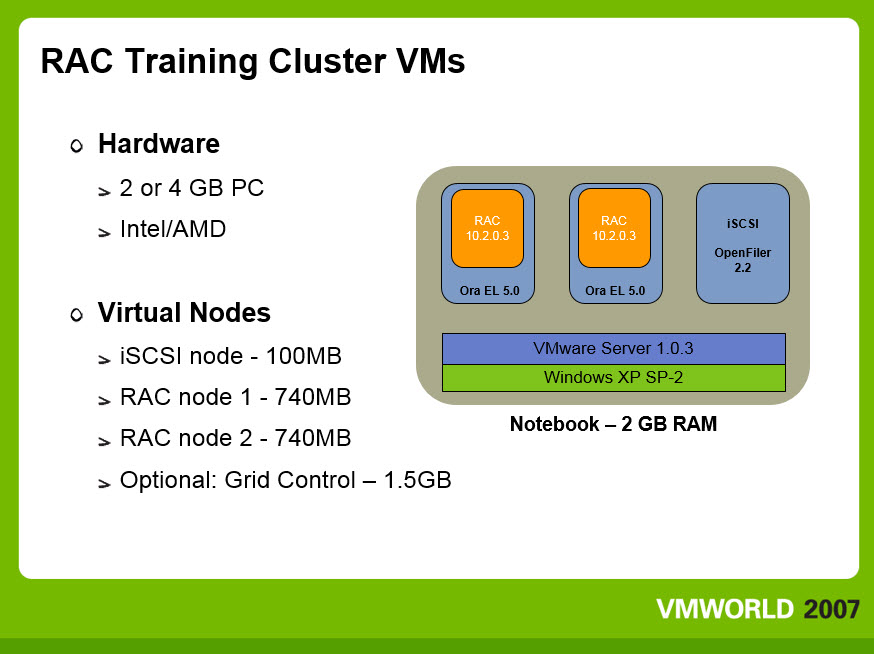
The benefits of RAC on VMware are illustrated by an experience that completely transformed over a dozen partner training providers’ Oracle University RAC experience. We taught Oracle University’s first RAC on VMware class back in 2007. Our O.U. coordinator had shared other O.U. partner training providers’ consistent nightmares in losing substantial time and student hands-on experience to troubleshooting classroom RAC stacks. RAC is complex, and in the span of novices’ full ground-up stack configuration, it’s easy to make a wrong turn. We were told that when diagnostics time loss got critical, four or more students would find themselves combined onto one of the classroom’s dwindling, still-functioning RAC stacks.
Everyone slips up now and then, so here’s our confession: In our first O.U. RAC class, we had mistakenly configured Clusterware’s Virtual IP manually, which led to erratic cluster lock-ups. Once we realized the problem and backed it out, the class operations were as smooth as glass. We did, of course, run into the same kinds (and number of) student-induced configuration problems as the other training partners’ classes. When we couldn’t diagnose and remediate quickly, we threw a DVD into the student notebook representing the desired stack progression for the labs at that point. Class lecture moved on without interruption as the troubled stack restored in the background. People are going to ask, so here’s the answer: over time, we variously ran the class using GSX and Player. We configured Workstation, too, at one point, but didn’t bring it into the classroom for licensing reasons.
And, no, we didn’t tell O.U. Tech Support in advance of our first class what we were up to out of concern that they would have pre-emptively shot down the configuration. Within months, our coordinator informed us that all O.U. RAC training partners had followed our lead and were teaching their RAC class on VMware. The vignette may be over a decade old but it’s still instructive. The same dramatic RAC on vSphere operational efficiencies are waiting for you.
Advantages of layering RAC on VMware include:
- VMware allows RAC-specific discoveries to happen at the earliest phases of the product development lifecycle
- RAC on VMware circumvents the need for each RAC cluster to have its own dedicated hardware
- RAC stacks can be stood up and cloned with minimal effort on the part of technical administrators
It is difficult to have routine operations more involved than those of a shop running RAC, let alone a shop developing for RAC. Therefore, many RAC organizations have a substantial backlog of revenue generating projects. VMware enables technical administrators to spend more of their time on projects applying their business knowledge. For all of these reasons, vSphere and RAC are quite complimentary technologies.
This is a great point at which to reread the ‘Operationally Test the RAC Stack’ section above. RAC on VMware allows you to telescope the RAC interconnect all the way back to the earliest phases of the architecture and development lifecycle, without any of the traditional RAC bare metal hardware dependencies. This opens the door for DBAs designing tests to exercise and monitor the application’s interaction with the interconnect as early as possible in the lifecycle.
The RAC Break/Fix Lab
A vSphere-enabled RAC stack opens the door to comprehensive stack failure trials that are unthinkable in bare metal environments. Every conceivable hardware and core technology failure and corruption can be induced into a virtualized stack. House of Brick’s RAC Break/Fix lab template includes a column for the client’s anticipation of both a given failure’s impact on the stack and the necessary remediation, as well as a place for journal entry of what actually happened (if different). It’s great fun to have the liberty to swing such a virtual sledge hammer without having to ask any hardware admin’s permission. Test your RAC to this level in a scoped trial, and you’ll have unparalleled confidence in both your RAC stack and your administration capabilities.
Next up, the series conclusion – Part III: The HA Feat RAC will Never Pull Off.


