



Jim Hannan (@jim_m_hannan), Principal Architect
Back in 2014, I wrote a blog VMFS vs. RDM Part 1, and with the introduction of vSphere 6 and VVols (Virtual Volumes), I thought the time was right for Part 2. In part 2, I take a look at what VVols can offer, and would say that in most cases VVols are an absolute replacement of RDMs.
The VVols technology, along with vSphere 6, has been available since 2015 but the implementation of VVols has been slow. To be fair, some of the adoption of VVols has been slowed due to the lack of storage vendor support. However, with the release of vSphere 6.5, further enhancements have been made to vSphere APIs for Storage Awareness (VASA) and VVols.
Note: HoB recommends that you follow your storage vendor’s best practices. Most vendors have published white papers and guides for presenting storage to vSphere.
What are VVols?
VVols are virtual volumes that are presented to the host, but unlike VMFS, they do not have a file system. Conceptually, they have some characteristics that more closely resemble a traditional LUN than that of a VMFS file system. More specifically, VMware describes VVols as a storage objects that are part of a storage pool. For example, for every virtual disk a VVol is created. The creation of a virtual disk on a VVol creates a VMDK pointer to the VVol.
VVols Architecture
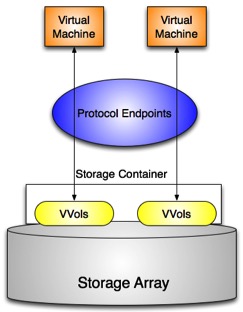
The core component of VVols architecture is the VASA/VVol supported storage array (gray in the image below). The Storage Container (white in the image below) creates logical volumes for the VVols to consume. The Protocol Endpoints are logical I/O proxies for communicating with the VVols (yellow in the image below).
Why Use VVols?
Snapshots: Removing a file system layer (like VMFS) allows the virtual objects to use SAN tooling like snapshots. For a virtual machine using VVols, you can do a storage array snapshot instead of a vSphere-based snapshot. This offers a great advantage for databases where vSphere snapshots are problematic because of the impact on performance (introduces more random I/O) and the creation of very large snapshots.
Replication: Volumes can be replicated with array tooling at a granular level, instead of entire datastores that may contain multiple virtual machines.
Deduplication: Array based deduplication to optimize storage capacity.
Clones: In addition to SAN level snapshots, cloning and restores are much faster with VVols than vSphere based clones or restoring VMDKs.
Familiar Setup: The process of setting up VVols is very intuitive in the vSphere interface. It feels like setting up a tradition datastore.
UNMAP: VVols do not have dead space or UNMAP issues like thin provisioned VMDKs do.
Better Capacity: Helps prevent wasted disk space by allocating only what is needed. For example, when a virtual machine is started a VVol is created for the swap file.
Storage Policies: Storage Policy Based Management (SPBM) provides ease of management and configuration. You can automate the storage by defining properties in the policy, like using only SSD or traditional spinning disks. Other capabilities include compression, deduplication, and replication.
Conclusion
As storage vendors begin to more readily support VVols, I see this becoming a new best practice for deploying virtual machines, over RDMs or VMFS file systems.


